Introduction
The word Plamatio comes from combination of p from my name (Pranav) and lama from the word Llama. Plamatio begin as a project to build an e-commerce frontend and backend for my portfolio in the form of a web store selling products inspired by Llamas. The project quickly grew into a full-fledged e-commerce platform with a scalable distributed backend, efficient frontend, and real-time data streaming for analytics and observability.
Gradually, Plamatio turned into an offering of open-source projects on which anyone could their own data-intensive, production-quality applications that demand high scalability, performance, and reliability.
I quickly realized that the core principles on which Plamatio was being built are commonly shared among all major production applications, at least those that involve high user interaction, require low-latency data fetching, and demand real-time synchronization of data among multiple platforms.
Plamatio Home Page
Core Principles
- Maintainability: The codebase should be easy to maintain and extend. This also involves being vendor neutral where possible, and using open-source technologies that are widely adopted.
- Scalability: The application should be able to scale horizontally and vertically with ease. This involves using distributed systems, microservices, and cloud-native technologies.
- Low-Latency Request Processing (Backend): The backend should be able to process requests with low latency, and should be able to handle a large number of concurrent requests.
- Cost-Effective & Responsive Frontend: The frontend should be able to fetch data efficiently, and should be able to render the UI with minimal latency. This involves using efficient data fetching strategies, and optimizing the UI rendering.
- Modularization At All Levels: The application should be modularized at all levels, including the frontend, backend, and data streaming components. This involves using microservices, and breaking down the application into smaller, manageable components.
- Clean, Accessible, and Responsive UI: The UI should be clean, accessible, and responsive. This involves using only the necessary UI frameworks, and following best practices for UI design.
- Single Source of Truth: The application should have a single source of truth for data, and should be able to synchronize data in real-time across multiple platforms. This involves using real-time data streaming technologies, and ensuring that data is consistent across all platforms.
- Observability, Logging, and Tracing: The application should be observable, and should provide detailed logs and traces for debugging and monitoring. This involves using logging and tracing frameworks, and ensuring that the application is instrumented for monitoring.
- Don’t Reinvent the Wheel: The application should use existing libraries and frameworks where possible, and should avoid reinventing the wheel. This involves using open-source libraries, and contributing back to the community where possible.
The result of above core principles is a production-quality scalable and distributed backend (Go, PostgreSQL) paired with an efficient frontend (Next.js, Redux, TypeScript) and real-time data streaming (Apache Kafka) for analytics and observability.
Below image displays an overview of the overall architecture of Plamatio:

Let’s go through some of the principles guiding the development of some of the core components, and have a look at their overall architecture and some of the complexities involved in their development and implementation.
Frontend
Plamatio Frontend is built using React, Next.js, Redux, TypeScript, and Tailwind CSS. The frontend is designed to be efficient, responsive, and cost-effective. It is modularized into several individual components, and follows best practices for UI design. There is also in-built instrumentation for monitoring, and provides detailed logs and traces for debugging and monitoring.
Overall Architecture
Below image displays an overview of the overall architecture of Plamatio Frontend:

Key Features
- Next.js: Built with Next.js, a React framework that enables server-side rendering and static site generation for faster content loading and improved SEO.
- Redux / RTK-Query: Uses Redux and RTK Query for efficient side effects and state management. Reduces latency in page loads and calls made to backend API for data fetching with optimal data caching with strategic invalidation.
- TypeScript: Written in TypeScript, providing static type checking to catch errors early and improve code quality and maintainability.
- Tailwind CSS: Utilizes Tailwind CSS for styling, allowing for rapid UI development with a utility-first approach and ensuring a consistent design system.
- Event data streaming: Streams user events to a Kafka pipeline, enabling real-time analytics and monitoring of user interactions.
- Real-time cross-platform updates: Listens to specific Kafka topics for updates to core components like cart and orders, ensuring real-time synchronization across different platforms.
- Component-based development: Follows a component-based architecture, promoting reusability, maintainability, and scalability of UI components.
- Clerk: Using Clerk for user authentication. A duplicate entry exists in the Plamatio backend for each user with user’s data. This is done to reduce vendor dependency and to ensure referential integrity of data on the backend side.
- Stripe: Integrates with Stripe for payment handling. Plamatio frontend primarily uses the Stripe’s JS SDK and Embedded Form, with price IDs setup in Stripe.
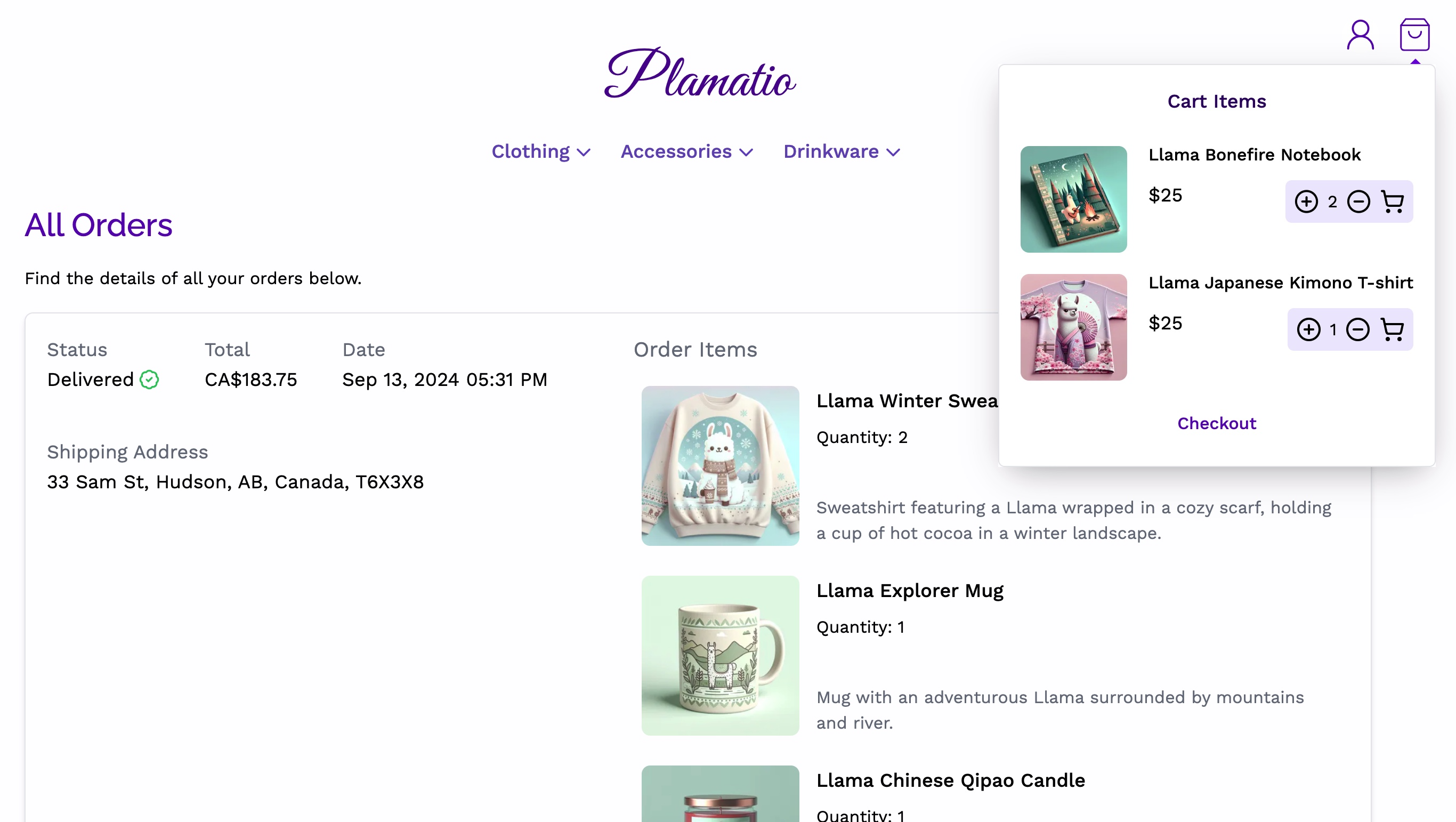
Plamatio Frontend with Cart Items and Orders in View.
Complexities
Efficient State and Side Effects Management
Plamatio Frontend uses Redux for state management and for handling side effects. Redux is used to manage the application state, and to handle side effects such as fetching data from the backend, posting data updates, and handling invalidation of cached data on data updates.
When there is no active user session (i.e., no signed in user), redux store data is stored in local storage, for example, local storage will store the cart items, and the user session data. This is done to ensure that the user’s cart items are not lost when the user closes the browser window, or when the user refreshes the page.
Displaying Up-to-Date Data in Real-Time
When there is an active user session, the data changes need to be recorded in the backend so that the backend database can serve as an up-to-date single source of truth for all the multiple frontend sessions active on any device for any user. Therefore, in this case, the frontend uses RTK Query to fetch data and to handle invalidation of cached data on data updates.
Real-Time Updates
Frontend also acts as a consumer to certain Kafka topics like cart_updates, order_updates, etc., to receive real-time updates from the backend. This is done to ensure that the user’s cart items are updated in real-time when the user adds or removes items from the cart, and to ensure that the user’s order status is updated in real-time when the user places an order.
Merging Local Cart Items with Backend Cart Items
When the user signs in, the frontend needs to merge the local cart items stored in local storage with the backend cart items stored in the backend database. This is done to ensure that the user’s cart items are not lost when the user signs in, and to ensure that the user’s cart items are consistent across all the multiple frontend sessions active on any device for any user.
This is a complex tasks because it requires the handling of several edge cases. For example, the user may have the same item in both local storage and the backend database but with different quantities. How do you decide which one takes precedence? Then there is also the challenge of user signing out and continuing updating cart items and then signing back in. How do you ensure that the cart items are consistent across all the multiple frontend sessions active on any device for any user?
The solution implemented in Plamatio Frontend is not perfect or complete, but it handle most edge cases and ensures that the user’s cart items are consistent across all devices.
Capturing User Interactions
Frontend also captures certain user interactions, such as clicking on a product, updating cart quantity of a product, viewing a sub-category, etc. This is done to track user behavior, and to provide insights into how users interact with the application. To enable this the frontend published messages to the user_events Kafka topic, which is then consumed by the backend for further processing.
Payment Processing
Plamatio Frontend outsources the payment processing to a third-party payment gateway, which in this case is Stripe. When user initiates the checkout, cart items containing details of the products and quantities are provided to the Stripe checkout session, and a model is displayed to the user containing the embedded Stripe payment form. The user then enters the payment details, and the payment is processed by Stripe. Once the payment is successful, the user is forwarded to orders page.
User Authentication
Plamatio Frontend uses Clerk as a third-party authentication provider. Clerk provides a simple and secure way to authenticate users, and to manage user sessions. When a new user signs up, Clerk creates a new user account, and sends a verification email to the user. The user then verifies the email, and the user account is activated. When an existing user signs in, Clerk verifies the user credentials, and creates a new user session. The user session is stored in local storage, and is used to authenticate the user for subsequent requests.
For replication and to enable additional referential integrity on the backend side, the ID of the user generated on the Clerk is also stored in the backend database. This also helps reduce vendor lock-in and dependency on Clerk.
Backend
Plamatio Backend serves as the highly scalable and resilient core of the Plamatio eco-system. Some of the core principles that guide the development, maintenance, and extension of the backend are:
- Scalability: The backend should be able to scale horizontally and vertically with ease. This involves using distributed systems, microservices, and cloud-native technologies.
- Low-Latency Request Processing: The backend should be able to process requests with low latency, and should be able to handle a large number of concurrent requests.
- Resilience and Fault Tolerance: The backend should be resilient to failures, and should be able to recover from failures with minimal downtime.
- Ease of Maintenance: The backend should be easy to maintain and extend. This involves being vendor neutral where possible, and using open-source technologies that are widely adopted.
Following the above mentioned core principles, the Plamatio Backend consists of the following components:
- REST API written in Go: The REST API is written in Go using the Encore.go framework, and is designed to be highly scalable and efficient. It is modularized into several individual components, and follows best practices for API design.
- PostgreSQL primary database: The primary database used by the backend is PostgreSQL. It is used to store user data, product data, order data, and other application data.
- Redis cache: Redis is used as a cache to store frequently accessed data, and to improve the performance of the backend.
- Encore Cloud: Encore Cloud is used to deploy and manage the backend. It provides a scalable and resilient infrastructure for the backend, and ensures high availability and low latency for the application. It also acts as the secrets manager for the backend, and provides secure storage for sensitive data.
- Real-Time Data Updates: The backend publishes real-time updates to Kafka topics, which are then consumed by the frontend for real-time synchronization of data across multiple platforms.
For information, please check the documentation for Plamatio Backend.
Overall Architecture
Plamatio Backend’s REST API is a culmination of several distributed REST services.
When the user first loads the frontend, the categories service is used to pull information related to product categories and sub-categories available for the Plamatio store. In-practice, especially when using Next.js for web-based frontend, this is done on the server-side and the webpages and/or components are statically pre-generated and cached to improve performance and user experience.
Data related to products (like product name, image, etc.), is fetched from the products service. User information is interfaced through users service, which provides information related to users and their associated addresses. The cart service is used to manage user’s cart items, and the orders service is used to manage user’s orders.

Data Streaming
Plamatio uses Apache Kafka for real-time data streaming. Kafka is used to stream user events, cart updates, order updates, and other real-time data updates to the frontend for analytics and observability. Kafka provides a scalable and resilient infrastructure for real-time data streaming, and ensures high availability and low latency for the application.
Frontend to Backend
When considering the Frontend to Backend pathway, the frontend acts as the producer and the backend acts as the consumer. The frontend publishes messages to the user_events Kafka topic, which are then consumed by the backend for further processing. The backend processes the messages, and updates the backend database with the user events.
THe user_events Kafka topic is primarily used for recording user events, for example, user clicking a specific product, user updating cart quantity of a product, user viewing a sub-category, etc. This data can then be used for analytics and for creating personalized user preferences profiles using AI and Machine Learning.
Backend to Frontend
When considering the Backend to Frontend pathway, the backend acts as the producer and the frontend acts as the consumer. The backend publishes messages to Kafka topics like cart_updates, order_updates, etc., which are then consumed by the frontend for real-time synchronization of data across multiple platforms.
The frontend listening for messages on these events have in place the system to invalidate the pre-fetched and cached data when new data is available. This ensures that the user’s cart items are updated in real-time when the user adds or removes items from the cart, and to ensure that the user’s order status is updated in real-time when the user places an order.
Overall Architecture
Below image displays an overview of the overall architecture of Plamatio’s real-time data streaming pipeline:

Observability, Logging, and Tracing
The Backend observability, logging, and tracing is provided through the built-in modules of the Encore Cloud platform.
Encore Cloud
The below image displays a basic example for certain metrics that can be easily tracked through Encore.

The below image shows a simple example of a backend API call trace.
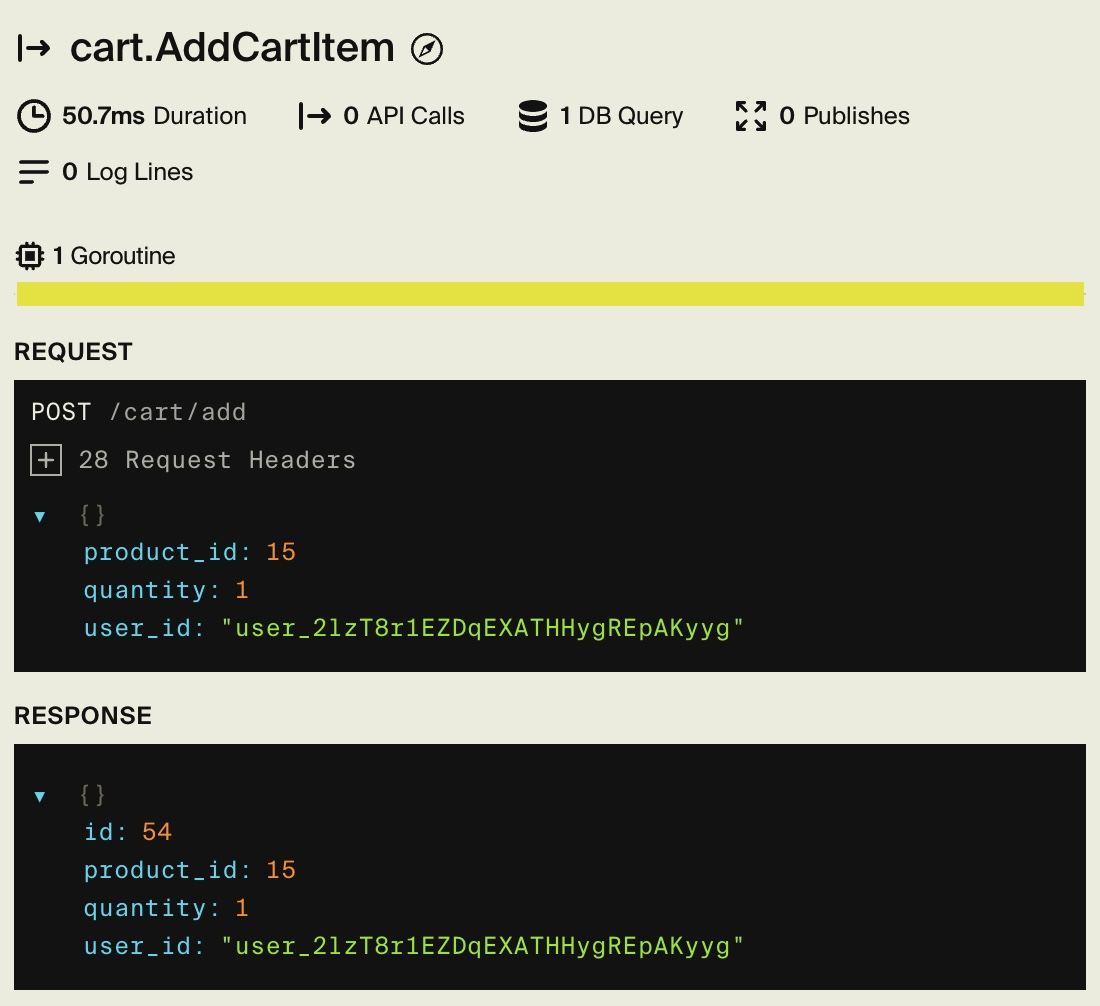
Example displaying trace of a request to add cart item.
The below image displays a web interface provided by Encore Cloud to test API endpoints for any of your environments (i.e., dev, staging, production).
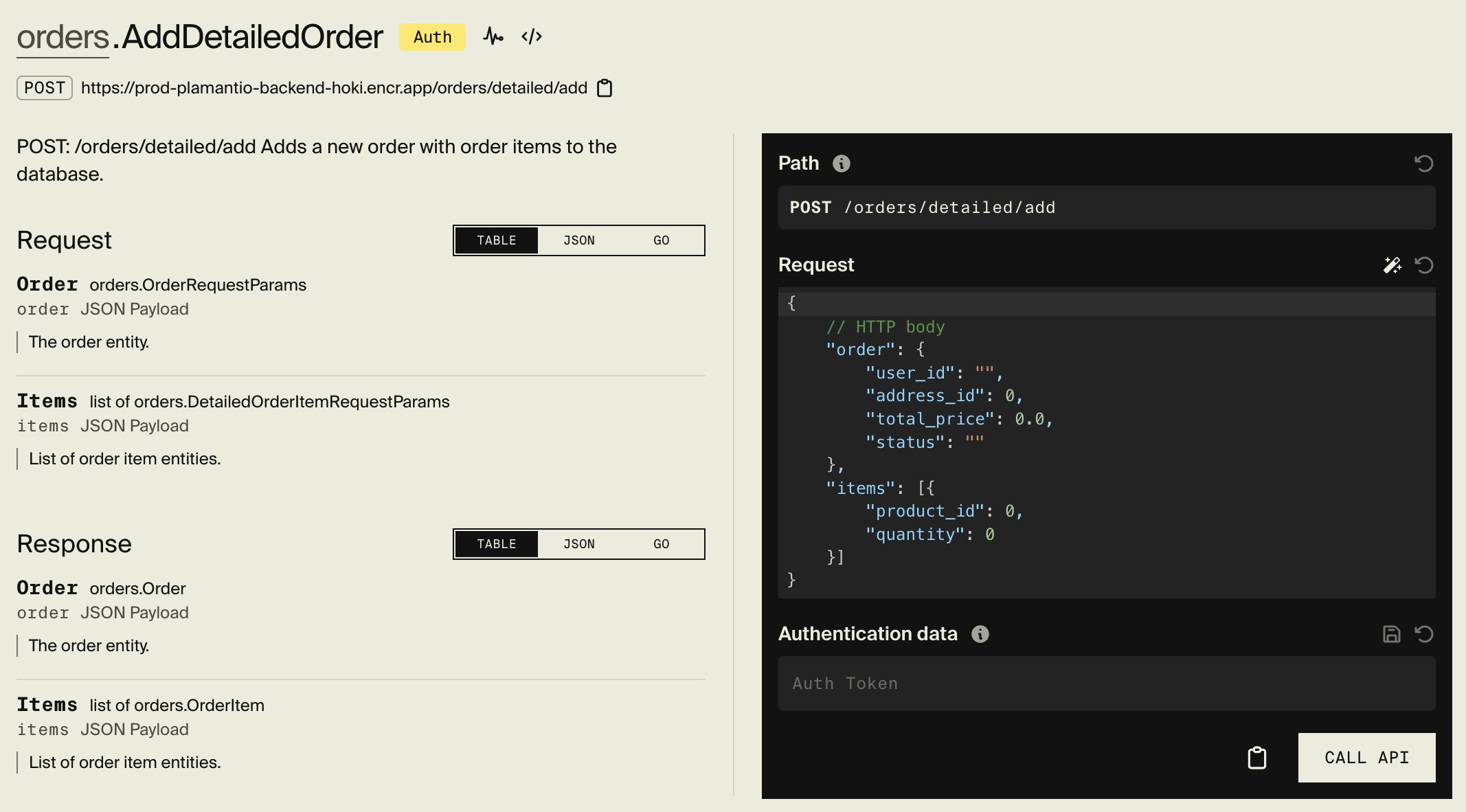
Example displaying API test interface provided by Encore Cloud.
Analytics
Plamatio’s web-based frontend is deployed using Vercel, and the analytics are provided through the built-in analytics module of Vercel.
For some specific use cases, like analytics specifically related to user activity, a data pipeline involving frontend, backend, Kafka, and a backend analytics module is used. The frontend streams user events in real-time to user_events topic, the messages on which are consumed by the backend and stored in the PostgreSQL database. The backend analytics module then processes this data to provide insights into user behavior, and to create personalized user preferences profiles using AI and Machine Learning.
Code & Repository Management
For the most part, the code is managed through GitHub. The codebase is divided into several repositories, each corresponding to a specific component of the Plamatio eco-system. The repositories are managed using Git, and are hosted on GitHub. The code is version controlled, and is managed using Git branches and pull requests.
There is also a CI/CD pipeline in place, which automatically builds and deploys the code to the production environment. GitHub Actions are also used for dependency management, code security scanning, and other automated tasks. This increases the speed of fixing bugs and releasing features for core components by taking off the burden of manual testing, deployment, dependency management, and more.
Future Direction
Plamatio is a work in progress, and there are several areas that need further development and improvement. Some of the areas that need further development and improvement are:
- AI and Machine Learning: Plamatio can benefit from AI and Machine Learning to provide personalized user experience, and to provide insights into user behavior. This involves using AI and Machine Learning algorithms to process user events data, and to create personalized user preferences profiles.
- Chatbot Integration: Plamatio can benefit from chatbot integration to provide real-time customer support, and to provide personalized product recommendations. This involves using chatbot integration to provide real-time customer support, and to provide personalized product recommendations.
Conclusion
The Plamatio project provides an eco-system of projects that enables the development of a production-quality e-commerce platform. It includes a scalable distributed backend, efficient and responsive frontend, and real-time data streaming for analytics and observability. With a clean, responsive design, and a highly-performant and resilient backend, Plamatio is designed to meet the needs of data-intensive, production-quality applications that demand high scalability, performance, and reliability, and top-notch user experience.
That being said, Plamatio is a work in progress, and there are several areas that need further development and improvement. Some of the areas that need further development and improvement are better analytics, providing personalized experience, chatbot integration, and more.
My hope through this post was to provide an overview of the core principles guiding the development of Plamatio, and to provide an insight into the complexities involved in the development and implementation of the core components of Plamatio. I hope that this article has been informative, and has provided you with a better understanding of the Plamatio project.
Below are some links to help your continue exploring more of Plamatio: