Multi-class classification empirical study using real textual data
coding project
deep learning
artificial intelligence
machine learning
natural language processing
Author
Pranav Kural
Published
December 3, 2023
Keywords
Deep Learning, Machine Learning, Artificial Intelligence, Natural Language Processing, NLP
Deep Learning Applied to Textual Data
In this notebook we will perform a classification empirical study using real textual data. The intention of this project is to present a comparative analysis of the performance of a supervised learning model (in our case Logistic Regression) and a deep learning model (in our case a Multi-Layer Perceptron Classifier) in the task of multi-class classification of airline passenger reviews.
Besides a detailed comparison of the performance of different types of models, we will also compare the changes in performance when using hyperparameter tuning and when using different types of preprocessed datasets.
To view a runnable version of this notebook you may choose from below options:
Code
# dependenciesimport numpy as npimport pandas as pdimport spacyfrom joblib import dump, loadimport matplotlib as mplimport matplotlib.pyplot as pltimport seaborn as snsimport seaborn.objects as so# set SNS themesns.set_theme(style="darkgrid", palette="Paired")from sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.model_selection import StratifiedKFoldfrom sklearn.linear_model import LogisticRegressionfrom sklearn.neural_network import MLPClassifierfrom sklearn.model_selection import cross_validatefrom sklearn.base import clone as clone_model
Data
Let’s begin by having a closer look and preparing our data.
I had the option of choosing from among three datasets.
Dataset selected: Airline Passenger Reviews. Please note that since this project is for demonstration purposes, for computational efficiency we will be using a reduced version of this original dataset. 1
Reason for selection:
Enough training data is available and the class imabalance is not too bad.
Did not choose the 4000 CNN articles dataset because of the presence of too many classes, and the difficulty of effectively classifying articles when there is an overlap, for example, an article about US and politics has to be categorized into only one of the categories, even though it may relate to both equally. Also, less training data is available in comparison to other datasets.
Did not choose the UCI Drug Review dataset because the substantial class imabalance in the dataset. One dominant condition “birth control” accounts for more than all other conditions combined (based on original dataset).
Generate two additional datasets
We will generate two additional datasets from our selected original dataset, so that we have three datasets to work with at the end:
Original Dataset
Derived-Dataset-1: contains subset of POS tags (Part-of-Speech tags)
Derived-Dataset-2: contains subset of named entities found in the text + some POS of importance
For example:
Original Dataset
Derived-Dataset-1 with only the verbs and adjectives lemmatized
Derived-Dataset-2 with 3 types of named entities (organizations, money and dates) and with adjectives lemmatized
In our classification experiments, we will test with these 3 datasets and compare results.
Original Dataset
We will be using a reduced version of the original dataset for this study. The dataset being used is openly available at: https://github.com/pranav-kural/deep-learning-textual-analysis/blob/main/reduced_file_AirPassengerReviews.csv
Code
# dataset locationds_url ='https://raw.githubusercontent.com/pranav-kural/deep-learning-textual-analysis/main/reduced_file_AirPassengerReviews.csv'# load original datasetoriginal_ds = pd.read_csv(ds_url)# display a short descriptionoriginal_ds.head()
customer_review
NPS Score
0
London to Izmir via Istanbul. First time I'd ...
Passive
1
Istanbul to Bucharest. We make our check in i...
Detractor
2
Rome to Prishtina via Istanbul. I flew with t...
Detractor
3
Flew on Turkish Airlines IAD-IST-KHI and retu...
Promoter
4
Mumbai to Dublin via Istanbul. Never book Tur...
Detractor
Understanding the data
Let’s do a basic statistical analysis of our data to know what we are going to be working with.
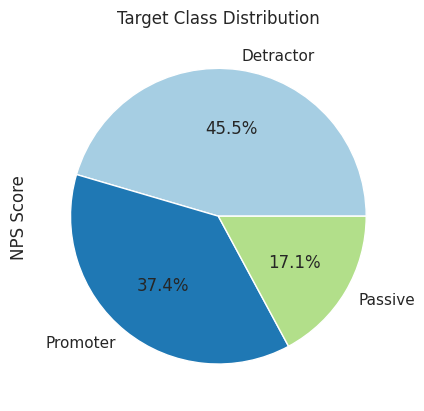
Let’s study the class distribution to be better aware of any class imabalance.
Code
# plot a pie chart to display class distributionoriginal_ds['NPS Score'].value_counts().plot(kind="pie",autopct="%.1f%%",title='Target Class Distribution')plt.show()
We can observe from the above that there is a slight class imbalance where we have a very small proportion of reviews belonging to the Passive category.
To handle this class imbalance, we can undertake a few approaches:
Drop some of the reviews belonging to the two dominant classes, so the class distribution is more uniform. Drawback: will loose some of the training data
Add more reviews belonging to the Passive category, either generated by humans or using a LLM.
Balanced Original Dataset
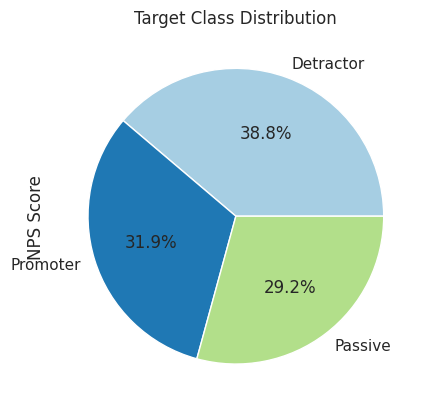
To keep things simple, we will use the second approach mentioned in the previous section to cater to the class imbalance in our original dataset. To later assess the impact of handling this class imbalance on the performance of our models, we will create a separate new dataset which will have a more uniform distribution of target class.
Code
# drop first half of the rows belonging to the class Detractordetractor = original_ds[original_ds['NPS Score'] =='Detractor']detractor = detractor.drop(detractor.index[len(detractor)//2:])# drop first half of the rows belonging to the class Promoterpromoter = original_ds[original_ds['NPS Score'] =='Promoter']promoter = promoter.drop(promoter.index[len(promoter)//2:])# get all rows belonging to the class Passivepassive = original_ds[original_ds['NPS Score'] =='Passive']# create a new dataset with a more balanced distribution of each target classoriginal_ds_balanced = pd.concat([detractor, promoter, passive])# shuffle the rows of the new dataset after combining target class datasetsoriginal_ds_balanced.sample(frac=1)# display the number of rows belonging to each classprint(original_ds_balanced['NPS Score'].value_counts())# plot a pie chart to display class distributionoriginal_ds_balanced['NPS Score'].value_counts().plot(kind="pie",autopct="%.1f%%",title='Target Class Distribution')plt.show()
Original Dataset row count: 10761
Original Balanced Dataset row count: 6301
Going forward, we will use a flag to ascertain whether we want to use balanced dataset (with less training examples) or the original dataset.
Code
# flag to specify if balanced dataset is to be useduse_balanced_dataset =True# ds will be the datset used from now for original datads = original_ds# if using balanced data, set ds to balanced datasetif use_balanced_dataset: ds = original_ds_balanced
NLP Pipeline
Before we can derive our two additonal datasets, we need to define our NLP pipeline using spaCy.
We are going to load the en_core_web_sm English pipeline provided by spaCy since its well optimized for CPU processing.
Code
# load the NLP pipelinenlp = spacy.load("en_core_web_sm")
Applying the pipeline to every sentence creates a Document where every word is a Token object.
Doc: https://spacy.io/api/doc
Token: https://spacy.io/api/token
Code
# specify column name to store tokens of reviewsds_tokens_col ='tokenized'# apply NLP pipeline to the column that has sentencesds[ds_tokens_col] = ds['customer_review'].apply(nlp)# display top 5 rows to view the results of NLP piepline processingds.head(5)
customer_review
NPS Score
tokenized
1
Istanbul to Bucharest. We make our check in i...
Detractor
( , Istanbul, to, Bucharest, ., We, make, our,...
2
Rome to Prishtina via Istanbul. I flew with t...
Detractor
( , Rome, to, Prishtina, via, Istanbul, ., I, ...
4
Mumbai to Dublin via Istanbul. Never book Tur...
Detractor
( , Mumbai, to, Dublin, via, Istanbul, ., Neve...
5
Istanbul to Budapest via Dublin with Turkish ...
Detractor
( , Istanbul, to, Budapest, via, Dublin, with,...
6
Istanbul to Algiers, planned to take off at 9...
Detractor
( , Istanbul, to, Algiers, ,, planned, to, tak...
Utility methods
Before we continue with processing the tokens, let’s define two utility methods that we will be using later to derive additional datasets.
Code
# method to extract wanted POS from the given sentences containing tokensdef get_pos(sentence, wanted_pos): pos = []for token in sentence:if token.pos_ in wanted_pos:# add the lemmatized text of the token to result pos.append(token.lemma_) # lemma returns a number. lemma_ return a stringreturn' '.join(pos) # return value is as a string and not a list for countVectorizer# method to extract wanted Named Entities (NE) & POS tags from given sentences containing tokensdef get_ne_and_pos(sentence, wanted_ne, wanted_pos): ne = []for token in sentence:# if current token belongs to one of the wanted Named Entities & POSif (token.ent_type_ in wanted_ne) or (token.pos_ in wanted_pos):# add the lemmatized text of the token to result ne.append(token.lemma_) # lemma returns a number. lemma_ return a stringreturn' '.join(ne) # return value is as a string and not a list for countVectorizer
Derived Dataset 1
For generating our first derived dataset, we will focus on following POS: ‘ADJ’, ‘ADV’, ‘NOUN’, ‘INTJ’
Reasoning
In terms of review analysis, the most important part-of-speech tags are adjectives, adverbs and nouns. Adjectives and adverbs are used to describe the sentiment of the text, while nouns are used to identify the subject or object of the text. 2
We will also include interjections in wanted POS tags, since they typically express an emotional reaction. 3
List of POS tags available here: https://universaldependencies.org/u/pos/
Code
# generate derived-ds-1# wanted POSwanted_pos = ['ADJ', 'ADV', 'NOUN', 'INTJ']# declare derived dataset (empty for now)derived_ds_1_tokens_col ='pos'derived_ds_1_class_col ='class'derived_ds_1 = pd.DataFrame(columns = [derived_ds_1_class_col, derived_ds_1_tokens_col])# add the wanted POS for each sentence to the POS column for each rowderived_ds_1[derived_ds_1_tokens_col] = ds[ds_tokens_col].apply(lambda sent : get_pos(sent, wanted_pos))# add the target class columnderived_ds_1[derived_ds_1_class_col] = ds['NPS Score']# verify the number of rowsprint("Original Dataset row count: ", ds.count()[0])print("Derived Dataset 1 row count: ", derived_ds_1.count()[0])# display first few rowsderived_ds_1.head(5)
GPE (Geopolitical entities): Certain cities, countries may be more likely to have a certain type of service quality or may tend to a majority of customers belonging to a certain category, for example London might have bad service and most customers going through London might have a higher tendency to give negative reviews.
PERSON, ORG: Mentioning people or organization by name may indicate reviewer expressing certain personal emotion.
DATE, TIME: Values such as “three hours late” may indicate a negative feedback, so are important to consider.
MONEY, ORDINAL: Its not common to mention monetary or ordinal values (like first, second, so on.) in passive reviews, so the inclusion of such values may indicate certain sentimental feedback.
PRODUCT: Can be used to identify certain product (like food) that the customer maybe satisfied or disatisfied with.
LANGUAGE: Its not common for customers to mention language in review, so it may indicate to strongly positive or negative experience.
EVENT: Customer may mention specific events in their review to explain certain special experiences they might have experienced whether positive or negative.
Code
# generate derived-ds-2# wanted POS & Named Entitieswanted_pos = ['ADJ', 'ADV', 'NOUN', 'INTJ']wanted_ne = ['GPE', 'PERSON', 'ORG', 'DATE', 'TIME', 'MONEY', 'ORDINAL', 'PRODUCT', 'LANGUAGE', 'EVENT']print("Verify the implementation of our named entity extraction. Using first review in dataset as example.")print("\nOriginal Text (first 20 characters): ", ds[ds_tokens_col][0][:20])print("After extraction of wanted named entities (from complete review text): ", get_ne_and_pos(ds[ds_tokens_col][0], wanted_ne, wanted_pos)[:50])# declare derived dataset (empty for now)derived_ds_2_tokens_col ='ne_and_pos'derived_ds_2_class_col ='class'derived_ds_2 = pd.DataFrame(columns = [derived_ds_2_class_col, derived_ds_2_tokens_col])# add the wanted Named Entities & POS tags for each sentence to the NE column for each rowderived_ds_2[derived_ds_2_tokens_col] = ds[ds_tokens_col].apply(lambda sent : get_ne_and_pos(sent, wanted_ne, wanted_pos))# add the target class columnderived_ds_2[derived_ds_2_class_col] = ds['NPS Score']# verify the number of rowsprint("\nOriginal Dataset row count: ", ds.count()[0])print("Derived Dataset 2 row count: ", derived_ds_2.count()[0], "\n")# display first few rowsderived_ds_2.head(5)
Verify the implementation of our named entity extraction. Using first review in dataset as example.
Original Text (first 20 characters): London to Izmir via Istanbul. First time I'd flown TK. I found them very good in
After extraction of wanted named entities (from complete review text): London Izmir Istanbul first time very good air cab
Original Dataset row count: 6301
Derived Dataset 2 row count: 6301
class
ne_and_pos
1
Detractor
Istanbul check airport luggage gate gate surpr...
2
Detractor
Rome Prishtina Istanbul company several time t...
4
Detractor
Mumbai Dublin Istanbul never book turkish airl...
5
Detractor
Istanbul Budapest Dublin Turkish Airlines dela...
6
Detractor
Istanbul Algiers 9:30 pm Algiers 11:20 pm same...
This concludes the derivation of two additional datasets. Now we have three datasets to work with:
derived_ds_2: derived dataset 2 (containing wanted named entities and POS tags)
Classification Empirical Study
1. Encode text as input features with associated values
Using scikit-learn we encode the text data as features which can than be used in our deep learning model. The text becomes a bag-of-words where each word becomes an independent feature.
We will also remove stopwords to reduce the corpus size and use tf-idf as attribute value.
Why use TF-IDF?
Using relative frequency of a word in the corpus allows for better identification of more important and meaningful words relative to the documents, instead of simply assigning the importance of a word based on its frequency in the corpus. For example, a word occuring more often in only two of the six documents would likely be more important and meaningful to those two documents, compared to a word that occurs more frequently in all the six documents. 4
# Logistic Regression with default parameterslg = LogisticRegression()# MLP Classifier with default parametersmlp_1 = MLPClassifier()
3. Train Test Evaluate
Now, we will train, test and evaluate previously defined two models (using default parameters) on the three datasets (original dataset, derived-dataset-1 and derived-dataset-2).
1. Train
For training the model, let’s define our cross validation instance to be used across all models. We will also create a method to help train the model and return the results based on scoring metrics specified.
We will be using 4-fold cross validation for each of the models, and assess each model’s performance based on precision and recall using both micro and macro averaging.
Code
# default cross validation using 4-fold splitsskf = StratifiedKFold(n_splits=4)# scoring metrics to use for cross validationscoring=['precision_macro', 'precision_micro', 'recall_macro', 'recall_micro']# set n_jobs to -1 to use multi-processing coresn_jobs =-1
Let’s define some utility methods to train models and obtain required scores.
Code
# method to use the 'cross_validate' function from scikit-learn to train and evaluate the model# returns a pandas dataframe containing results of scoring metricsdef train_model(mod, X, y, cv, scoring, n_jobs):# create a copy of the model# this prevents the same instance of model being re-trained if called twice estimator = clone_model(mod) scores = cross_validate(estimator, X, y, cv=cv, scoring=scoring, n_jobs=n_jobs) sp = pd.DataFrame() sp["p_macro"] = scores["test_precision_macro"] sp["p_micro"] = scores["test_precision_micro"] sp["r_macro"] = scores["test_recall_macro"] sp["r_micro"] = scores["test_recall_micro"]return sp# method to train and get scoresdef train_and_score_model(mod): scores = []# train models on each of the datasets datasets = [X_ds, X_derived_ds_1, X_derived_ds_2]# train models and append scoresfor X in datasets: scores.append(train_model(mod, X, Y_ds, skf, scoring, n_jobs))# return the scoresreturn scores# method to return mean scores for each of the datasets give the cross validation scoresdef return_mean_scores(scores): results=[] results.append(scores[0].mean().to_numpy()) # original dataset scores at index 0 results.append(scores[1].mean().to_numpy()) # derived 1 dataset scores at index 1 results.append(scores[2].mean().to_numpy()) # derived 2 dataset scores at index 2 results = pd.DataFrame(results) results.columns = scores[0].columns.to_numpy() results.index = ["Original Dataset", "Derived 1", "Derived 2"]return results
Now, let’s use the above define utility methods to train our models created using default parameters and obtain their scores.
Code
# train models and store the scoreslg_scores = train_and_score_model(lg)mlp_1_scores = train_and_score_model(mlp_1)# display mean scoresprint("\nLogistic Regression (with default parameters) Scores: ")print(return_mean_scores(lg_scores))print("\nMLP Classifier (with default parameters) Scores: ")print(return_mean_scores(mlp_1_scores))
We will now evaluate the precision/recall measures of each of the models. Since, we are working with a multi-class classification problem, we will be comparing both micro and macro averages.
Before we can begin evaluation though, let’s define some utility methods which will help in extraction of relevant metric scores and their visualization.
Code
# method to extract and combine results of model training and evaluationdef get_results(ds_1_scores, ds_2_scores, label_1="lg", label_2="mlp", columns="", indices=""):# store results results = []# calculate and append mean scores results.append(ds_1_scores.mean().to_numpy()) results.append(ds_2_scores.mean().to_numpy())# convert to data frame results = pd.DataFrame(results)# add columns and index values results.columns = columns results.index = indices# return resultsreturn results# function to generate visual graphs for comparison of precision and recalldef compare_results(ds_1_scores, ds_2_scores, mod_1="", mod_2="", kind='bar', figsize=(6,4)):# labels to differentiate dataset type dataset_names = ["(X_ds)", "(X_derived_1)", "(X_derived_2)"]# names of respective datasets corresponding to labels above dataset_titles = ["Original Dataset", "Derived Dataset 1", "Derived Dataset 2"]# for each of the datasetsfor i inrange(len(ds_1_scores)):# get column and indices names columns = ds_1_scores[i].columns indices = [f"{mod_1}{dataset_names[i]}", f"{mod_2}{dataset_names[i]}"]# get results from the model scores results = get_results(ds_1_scores[i], ds_2_scores[i], columns=columns, indices=indices)# plot a bar graph of the results results.plot(kind=kind, figsize=figsize, rot=0, title=dataset_titles[i]) plt.show()
Now, let’s visually examine the performance of our models on each of the datasets and compare their precision/recall micro and macro scores.
Code
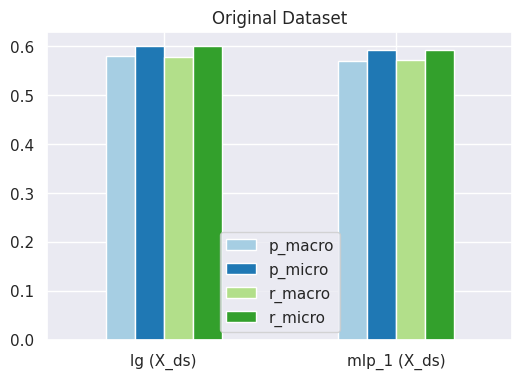
# compare precision and recall of our models on the three datasetscompare_results(lg_scores, mlp_1_scores, mod_1="lg", mod_2="mlp_1", kind="bar")
Observations:
Both our models instantiated with default parameters perform fairly similarly, although the logistic regression model seems to perform slightly better.
How the class imbalance impacts the micro/macro results?
If using the balanced dataset, we would notice only a small difference between the micro and macro averaging scores, since the target class is pretty uniformly distributed. However, if using the non-balanced (original) dataset, we would notice that scores for precision/recall based on macro averaging are generally lower than the micro averaging scores. We will discuss the reasons for this in detail later on.
Improving our MLP classifier model
Now, that we have examined the performance of our models with default parameters, we will modify some parameters of our MLP classifier model, and train, test and evaluate its performance again, to see how changes in parameters affect the model performance.
We will do this two times.
1. Attempt 1 - MLP model #2
Parameters being changed:
hidden_layer_size=(64,256,512,128,32)
Reasoning:
Let’s start by making a simple change in the number of hidden layers and the number of neurons in each of those hidden layers.
Please note that, the very empirical nature of working with deep learning models imply iterative experimentation to come on a consesus for relatively optimal values of a hyperparameter. As such, to find a “good” value for the number of hidden layers and the number of neurons, I had to perform experiments with different values, and then select the best performing.
Initial or default number of layers for MLPClassifier provided by scikit-learn is 100 neurons in 1 hidden layer (100,). 5
I gradually increased the number of layers and number of neurons in each layer until the model started to perform worse.
Here are some results from that experiment (only original dataset results shown here):
It is clear from above, that after a certain point, increasing the number or size of hidden layers starts to deteriorate model performance.
Code
# parameters# 5 hidden layers of sizes given belowhidden_layer_sizes=(64,256,512,128,32)# instantiate the new MLP modelmlp_2 = MLPClassifier(hidden_layer_sizes=hidden_layer_sizes)# train the new model on all three datasets and store the scoresmlp_2_scores = train_and_score_model(mlp_2)# display mean scoresprint("\nMLP Classifier model #2 Scores: ")print(return_mean_scores(mlp_2_scores))
Similar to the approach taken in the previous attempt, several iterative experiments were performed with various different values of hyper-parameters to come to these parameters and values.
Logical reasoning for why some of these parameters might be performing better:
SGD: Stochastic Gradient Descent or SGD, generalizes better than adaptive optimizers like Adam or RMSProp, although it is comparatively slower. 6
Early Stopping: Early stopping simply allows the training process to stop earlier if there is no significant improvement noticed in the validation accuracy after certain epochs.
Learning Rate: Using a slightly higher learning rate helps speed up the training process in the starting or model training. Combining it with adaptive learning rate ensures that our model doesn’t overfit on training data too early or that it gets stuck in a local maxima.
Code
# parametershidden_layer_sizes=(32,64,128)solver ='sgd'early_stopping =Truelearning_rate_init =0.01learning_rate ='adaptive'# instantiate the new MLP modelmlp_3 = MLPClassifier( hidden_layer_sizes=hidden_layer_sizes, solver=solver, early_stopping=early_stopping, learning_rate_init=learning_rate_init, learning_rate=learning_rate)# train the new model on all three datasets and store the scoresmlp_3_scores = train_and_score_model(mlp_3)# display mean scoresprint("\nMLP Classifier model #3 Scores: ")print(return_mean_scores(mlp_3_scores))
We will now quantitatively and visually compare the precision and recall measures of our 12 results. The 12 results come from 4 models (Logistic Regression + 3 variations of MLP) each applied on 3 datasets (Original + Derived1 + Derived2).
However, before we can dive into the analysis, let’s define some utility functions to help us compare and visualize data better.
Code
# index values to access specific dataset resultsorg_ds_idx =0d1_ds_idx =1d2_ds_idx =2# method to return mean score of dataset given by ds index# 0 -> Original Dataset, 1 -> Derived Dataset 1, 2 -> Derived Dataset 2def get_dataset_mean_scores(ds_idx):# store results results = []# calculate and append mean scores for each model results.append(lg_scores[ds_idx].mean().to_numpy()) results.append(mlp_1_scores[ds_idx].mean().to_numpy()) results.append(mlp_2_scores[ds_idx].mean().to_numpy()) results.append(mlp_3_scores[ds_idx].mean().to_numpy())# store in data frame results = pd.DataFrame(results)# update column and row names results.columns = lg_scores[ds_idx].columns results.index = ["lg", "mlp 1", "mlp 2", "mlp 3"]# return dataframe containing resultsreturn results# method to plot graph given results containing mean scores of all models for a specific datasetdef plot_results_graph(results, kind="bar", figsize=(11,5), title=""): results.plot(kind=kind, figsize=figsize, rot=0, title=title)# method to display lineplot for resultsdef results_lineplot(results, title=''): sns.relplot(data=results, kind="line", palette="tab10") plt.title(title) plt.show()
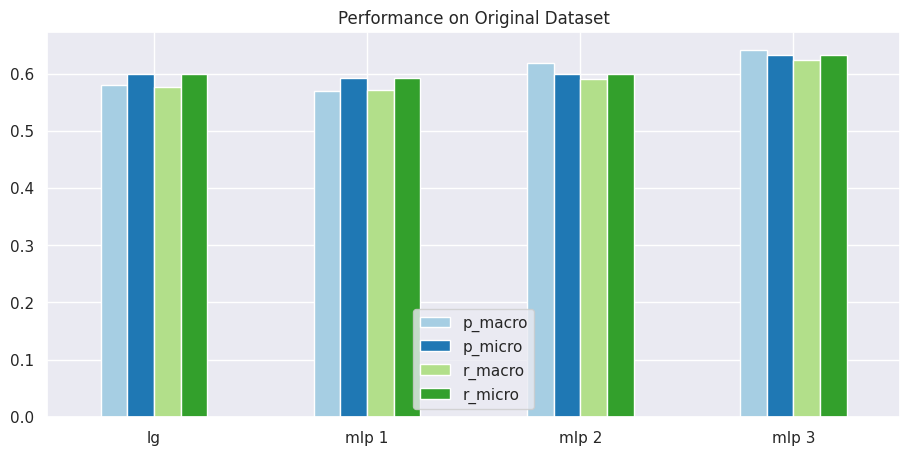
Comparison 1 - Original Dataset
In this comparison, we will check how our 4 models performed on the original dataset.
Code
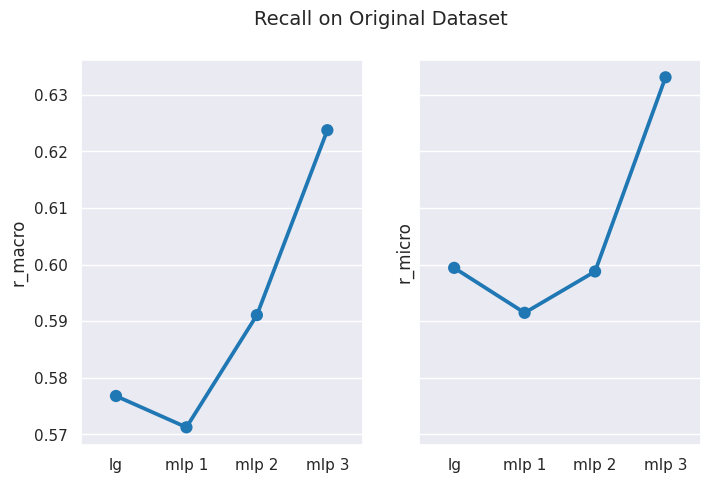
# obtain results for Original Datasetresults = get_dataset_mean_scores(org_ds_idx)results
p_macro
p_micro
r_macro
r_micro
lg
0.579376
0.599421
0.576800
0.599421
mlp 1
0.568668
0.591482
0.571270
0.591482
mlp 2
0.618024
0.598785
0.591078
0.598785
mlp 3
0.640886
0.633065
0.623728
0.633065
Code
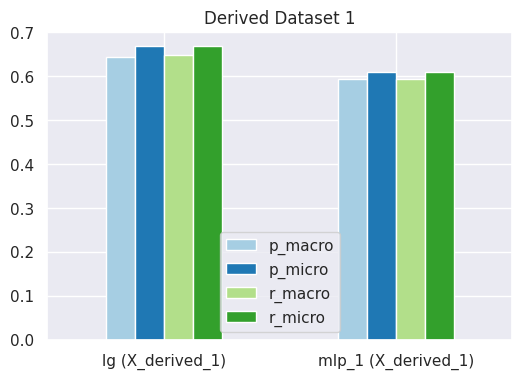
# visualize performance of each model on datasetplot_results_graph(results, title="Performance on Original Dataset")
As you can see above, the MLP classifier models with custom parameters performs better in all metrics than the models with default parameters.
Code
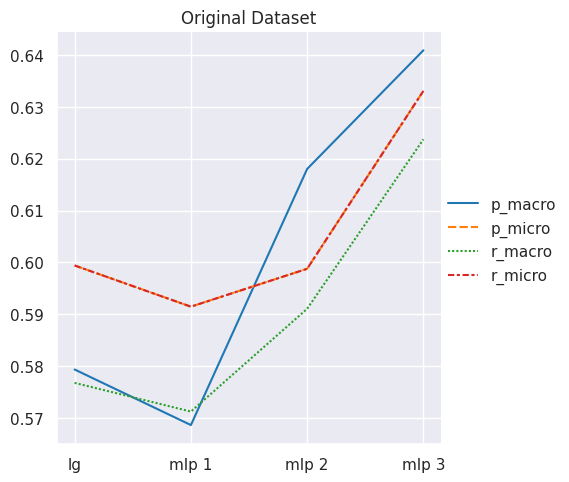
# plot lineplot to see performance trajectoryresults_lineplot(results, 'Original Dataset')
Observations
From above results and visualizations, it is clear that almost all metrics improve as we customize our MLP classifier model with more optimal hyper-parameters.
Initially, Logistic Regression performs better than MLP classifier, which is likely because our MLP classifier only contained a single hidden layer with a 100 neurons. Such a network is not well capable of fitting to non-linear and diverse data, such as textual data, that well.
MLP Classifier with greater number of layers and more neurons is better able to fit itself to the processed textual data and hence yields better results.
You may also notice that macro-averaging based precision and recall scores are slightly lower than the micro-averaging based precision and recall score. This is common in multi-class classification problem. We will discuss this later in detail.
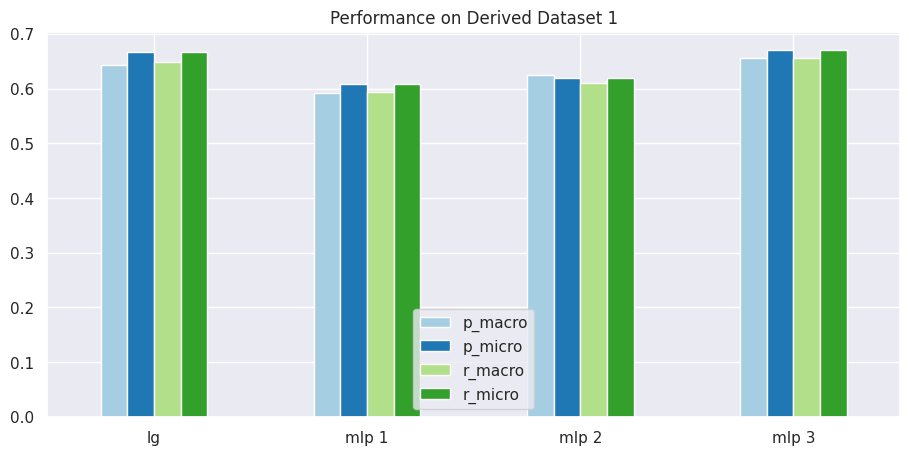
Comparison 2 - Derived Dataset 1
Code
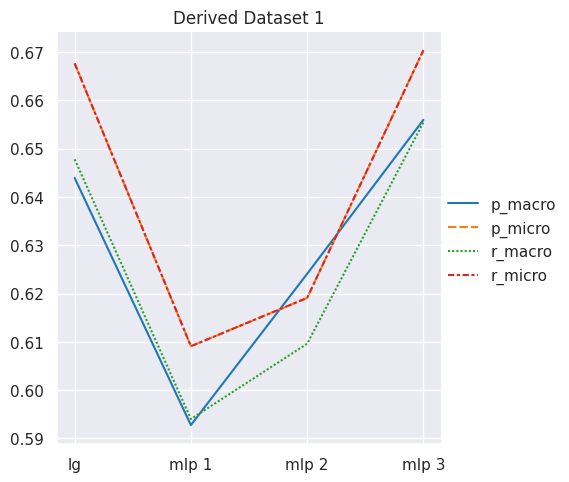
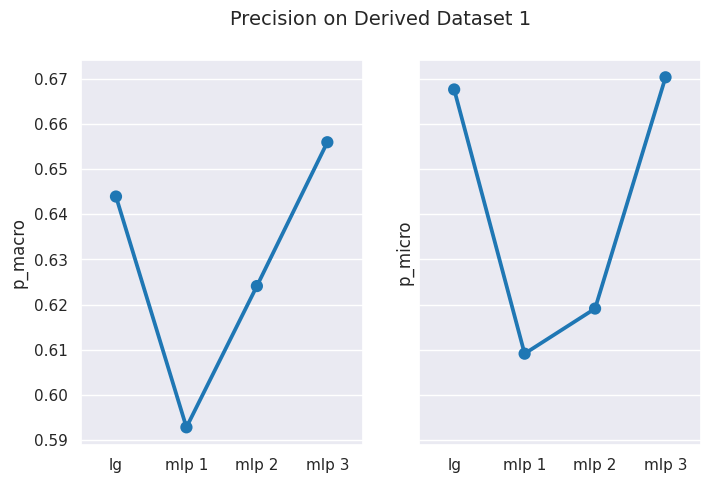
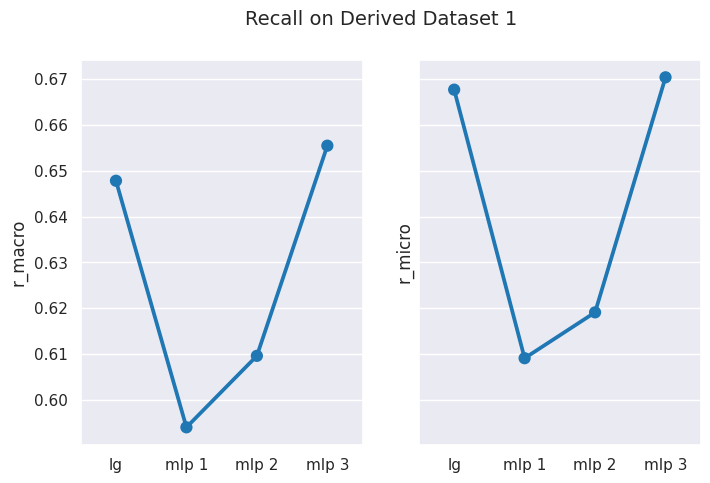
# obtain mean score results for Derived Dataset 1results = get_dataset_mean_scores(d1_ds_idx)results
p_macro
p_micro
r_macro
r_micro
lg
0.643936
0.667669
0.647802
0.667669
mlp 1
0.592780
0.609104
0.594034
0.609104
mlp 2
0.624089
0.619103
0.609622
0.619103
mlp 3
0.655973
0.670366
0.655453
0.670366
Code
# visualize performance of each model on datasetplot_results_graph(results, title="Performance on Derived Dataset 1")
As you can observe from above, MLP Classifier fails to gain subtantial edge over Logistic Regression, implying that in this case, we didn’t really obtain any additional benefit from deep learning compared to supervised learning.
If we are using the balanced dataset, you may also notice that macro and micro averages are quite similar, this is because of the low level of class imbalance in the dataset.
Code
# plot lineplot to see performance trajectoryresults_lineplot(results, 'Derived Dataset 1')
Observations
From above we can deduce that our deep learning model - MLP Classifier - fails to outperform our supervised learning based Logistic Regression model.
Why?
One reason why the supervised learning model may be performing quite well is because of the availability of large amounts of annotated data. We have over 6,000 labelled samples available to train our logistic regression model.
On the other hand, our MLP Classifier may be failing to perform well because of the lack of optimal hyper-parameter values. Hyper-parameter tuning in a case like this where the corpus size is substantially large is a compute and time intensive process.
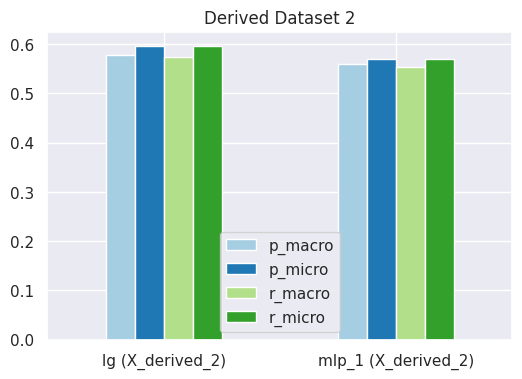
Comparison 3 - Derived Dataset 2
Code
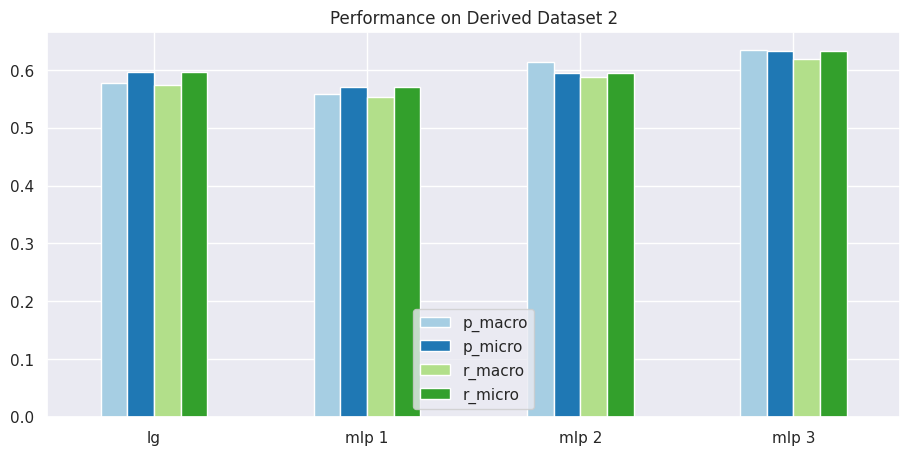
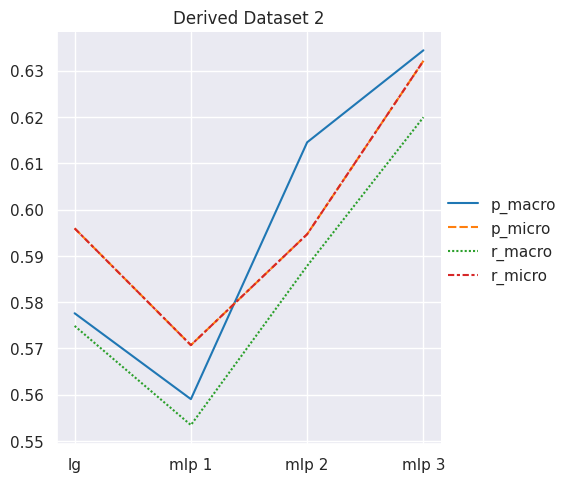
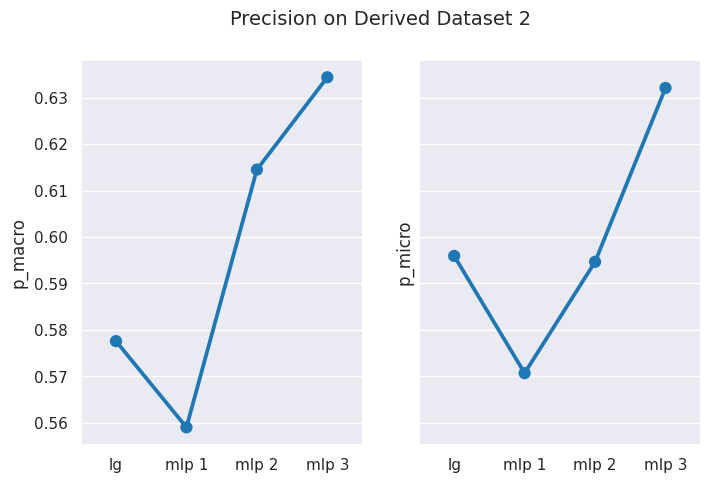
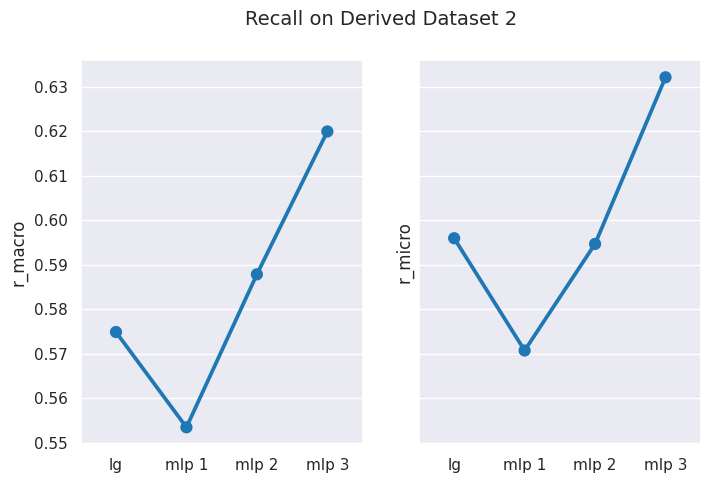
# obtain mean score results for Derived Dataset 2results = get_dataset_mean_scores(d2_ds_idx)results
p_macro
p_micro
r_macro
r_micro
lg
0.577579
0.595932
0.574841
0.595932
mlp 1
0.559019
0.570690
0.553418
0.570690
mlp 2
0.614525
0.594661
0.587816
0.594661
mlp 3
0.634407
0.632118
0.619935
0.632118
Code
# visualize performance of each model on datasetplot_results_graph(results, title="Performance on Derived Dataset 2")
From above you can notice that our logistic regression model and the first two variants of MLP classifier perform worse on the derived dataset 2, whereas, the MLP 3 variant is able to perform slightly better than other models. However, in general, all models perform less better with derived dataset 2 than with the derived dataset 1.
Code
# plot lineplot to see performance trajectoryresults_lineplot(results, 'Derived Dataset 2')
Observations
We get lower performance results from models with derived dataset 2, however we can notice that our MLP classifier model (variant 3) is able to perform better results than the supervised logistic regression model when training using this dataset.
One reason for MLP 3 performing better maybe the use of SGD optimizer, since it enables the model to generalize better, and our derived dataset 2 has larger set of features than the derived dataset 1 which only contains POS tags and not the NE tags.
Comparison 4 - Precision and Recall
Now, let’s compare the difference between micro and macro averaging based precision and recall scores for each dataset.
Code
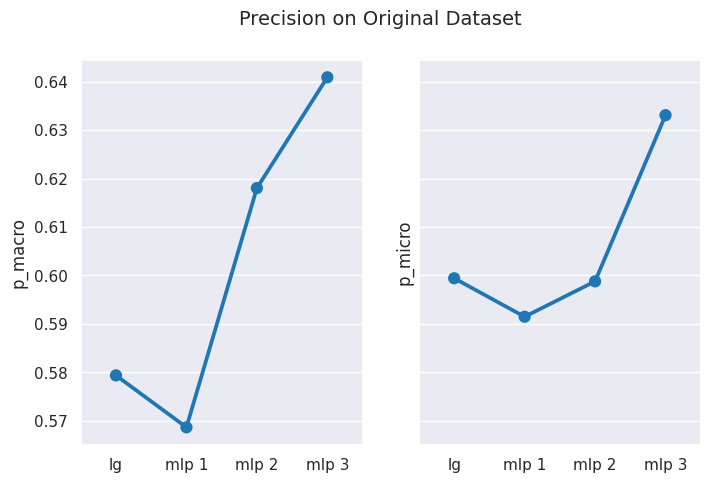
# update theme for clearer visualizationsns.set_theme(style="darkgrid", palette="tab10")# method to plot graph for metricdef plot_metric_result(results, metric_1, metric_2, title): fig, (ax1, ax2) = plt.subplots(ncols=2, sharey=True, figsize=(8, 5)) sns.pointplot(data=results, x=results.index, y=metric_1, ax=ax1) sns.pointplot(data=results, x=results.index, y=metric_2, ax=ax2) fig.suptitle(title, fontsize=14) plt.show()# Original Datasetresults = get_dataset_mean_scores(org_ds_idx)plot_metric_result(results, 'p_macro', 'p_micro', 'Precision on Original Dataset')plot_metric_result(results, 'r_macro', 'r_micro', 'Recall on Original Dataset')# Derived Dataset 1results = get_dataset_mean_scores(d1_ds_idx)plot_metric_result(results, 'p_macro', 'p_micro', 'Precision on Derived Dataset 1')plot_metric_result(results, 'r_macro', 'r_micro', 'Recall on Derived Dataset 1')# Derived Dataset 2results = get_dataset_mean_scores(d2_ds_idx)plot_metric_result(results, 'p_macro', 'p_micro', 'Precision on Derived Dataset 2')plot_metric_result(results, 'r_macro', 'r_micro', 'Recall on Derived Dataset 2')
Observations
You can clearly observe that scores using macro-averaging are usually lower than those measured using micro-averaging.
Why?
In a multiclass classification setting, the macro-average precision and recall scores are lower than the micro-average ones. This is because the false negatives of some classes are higher than that of other classes due to class imbalance. Therefore, the macro-average metric is more sensitive to the performance of the minority classes, while the micro-average metric is more sensitive to the performance of the majority classes. 7
Summary
In this project:
We examined the Airline Passengers Review dataset and took necessary steps to handle target class imbalance
We used spaCy for tokenization, lemmatization, POS tagging and Named Entity Recognition
We generated two additional datasets to train models on, so there datasets available for training were:
Original Dataset
Derived Dataset 1 - containing wanted POS
Derived Dataset 2 - containing wanted POS and NE
We trained two models, one supervised learning based Logistic Regression model and a deep learning based MLP classifier, on our three datasets, using default parameters
We tweaked hyper-parameters of our MLP classifier to obtain two new variants of MLP classifier, and trained these models on all three datasets
Finally, we performed a detailed comparative analysis of the results obtained from our model train, testing and evaluation
In conclusion, though our MLP classifier neural network performed fairly well, the availability of large amounts of labelled data ensured that our supervised learning based Logistic Regression model didn’t fall behind on precision or recall metrics. However, if better and more efficient ways of catering to the empirical part of finding optimal hyper-parameters for the neural network based model can be found, then it may yield better results and accuracy.