What is this project about?
As per FRAGMENT’s documentation:
FRAGMENT is a toolkit for building products that move and track money. It includes an API and Dashboard for designing, implementing, and operating your Ledger.
The goal of this project is to build a specialized reliable and accurate AI Assistant that can help users answer queries related to FRAGMENT (API, SDKs, etc.).
The AI Assistant will be powered by RAG (Retrieval-Augmented Generation) model with the FRAGMENT documentation website serving as source of ground truth and knowledge base. Along with the AI Assistant, this project also demonstrates handling of source data updates in the knowledge base (or vector store) more efficiently and in real-time.
How does it work?
Let’s review the problem statement:
We need the ability to get answers for our queries related to FRAGMENT in natural language. We also need to ensure that the answers are accurate and reliable. The answers should be generated based on the latest information available in the FRAGMENT documentation website.
Based on above, a few things are clear:
- Source of Information: FRAGMENT documentation website.
- Solution to answering queries in natural language: Large Language Model (LLM).
- Enriching user queries with FRAGMENT specific information: Retrieval-Augmented Generation (RAG) model.
- Handling updates in the source data: Effective data management of the knowledge base (vector store).
High-level Overview
This project scraps the data from FRAGMENT’s documentation webpages, prepares it, and then stores it as vectors or embeddings in a vector store. On receiving a query, the front-end chat interface first fetches the relevant pieces of information from our vector store that best relates to the query being asked, and then uses an LLM to generate the final answer. The answer is then displayed to the user in the chat interface.
Although, this sounds simple, but there are a lot of moving pieces and parts required in the backend to make this happen reliably, efficiently, and at scale. Let’s go through these parts next to better understand how it all works.
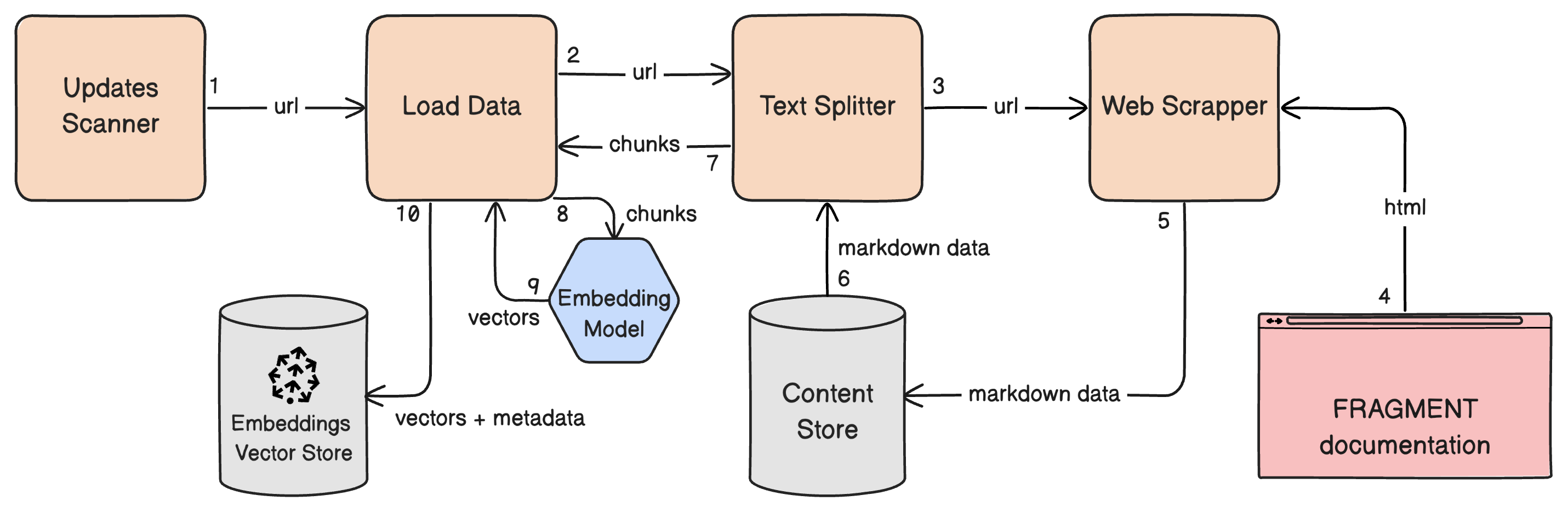
Components
- Updates Scanner: Scans the FRAGMENT documentation website for updates. If it detects changes for any given webpage, it triggers the data ingestion pipeline to update the knowledge base specifically for that webpage.
- Load Data: On receiving a URL (likely of a webpage from FRAGMENT documentation), this component fetches prepared data of the given URL webpage and loads it into the vector store after generating embeddings.
- Text Splitter: Given a URL, this component initiates the process of downloading content from the webpage. Once content is available, it will split the data using an appropriate splitting (and/or chunking) strategy and return the split data.
- Web Scrapper: This component is responsible for fetching the content of the FRAGMENT documentation webpages. It will download the content of the webpage and stores it at an accessible place.
Below image depicts how these components interact with each other at a high-level:
Components and Process Flow
Below you can find links to the source code of these components, in case you want to know more a particular component:
Data Ingestion Process Flow + Handling Ground Truth Updates
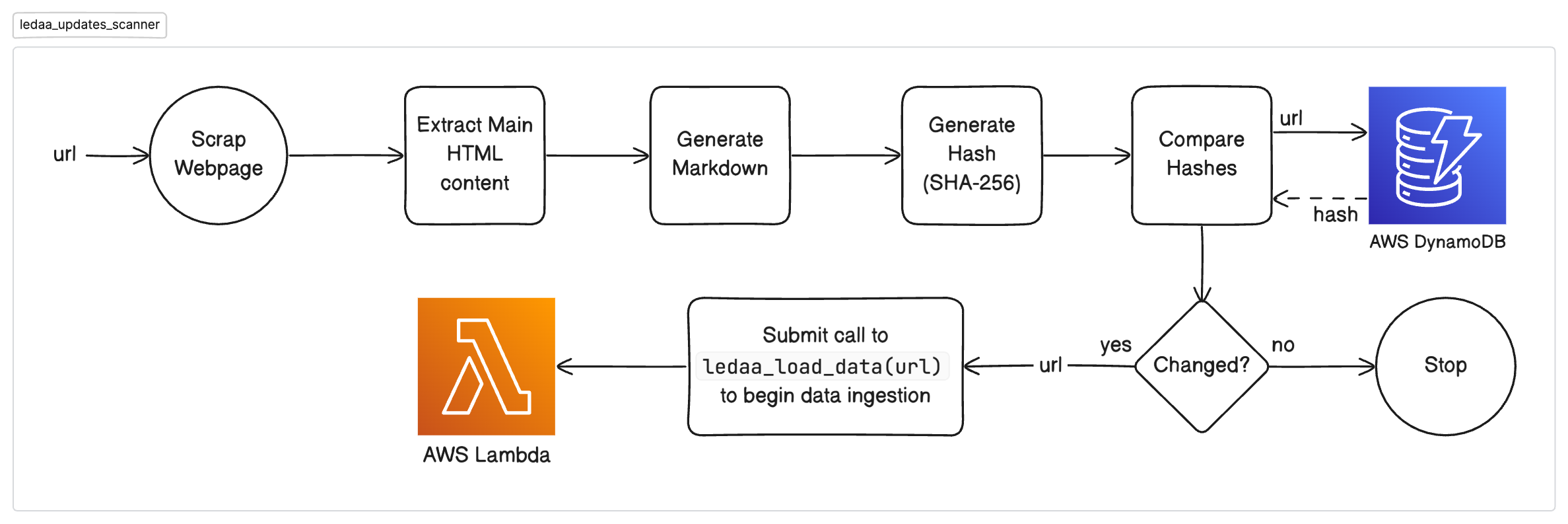
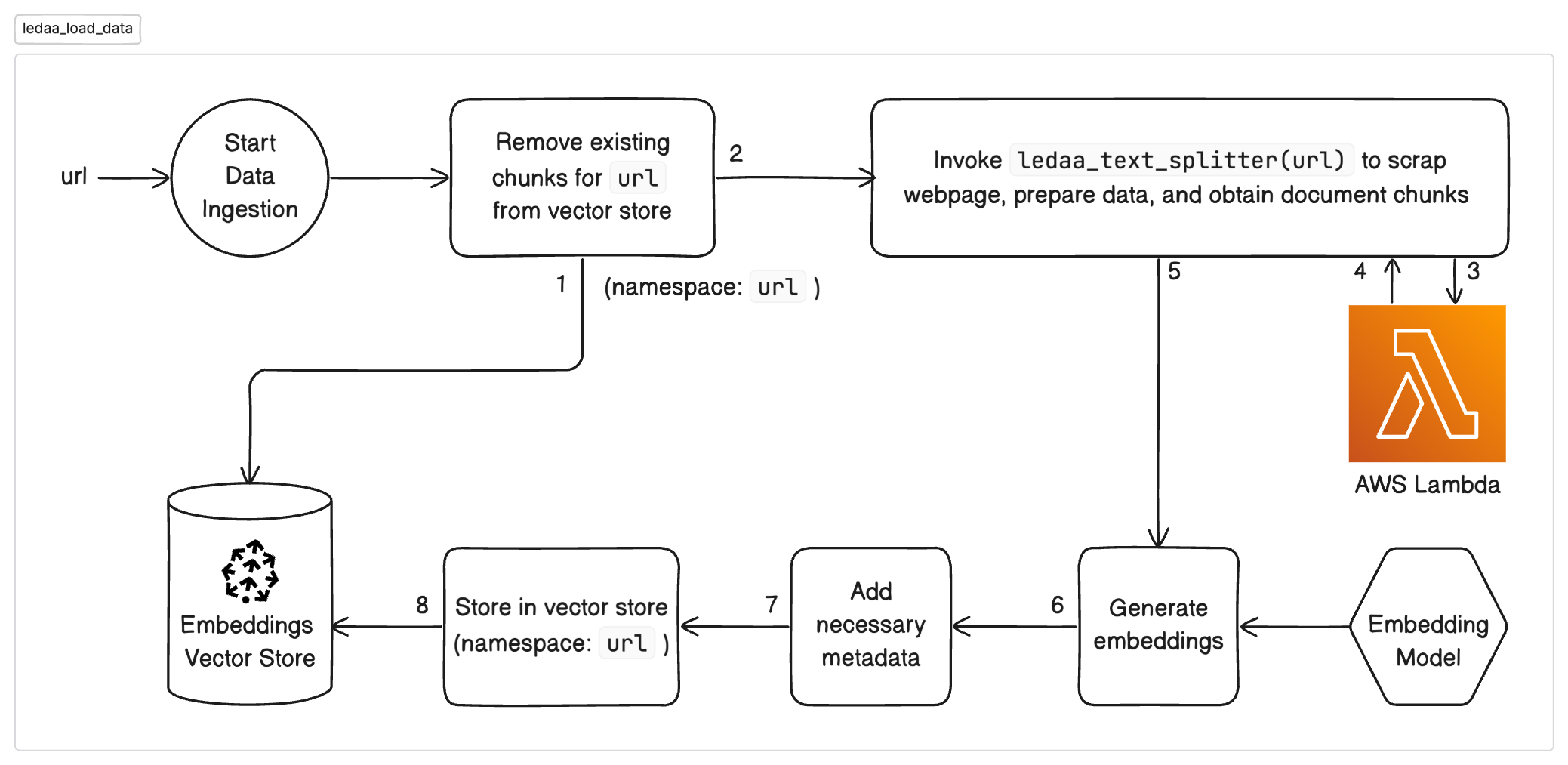
Below is the process flow for ingesting source data. It also shows how ground truth data updates are handled and how the knowledge base is updated efficiently and in real-time:
ledaa_updates_scannerLambda function monitors for changes in content of documentation.- On detecting changes, it triggers the
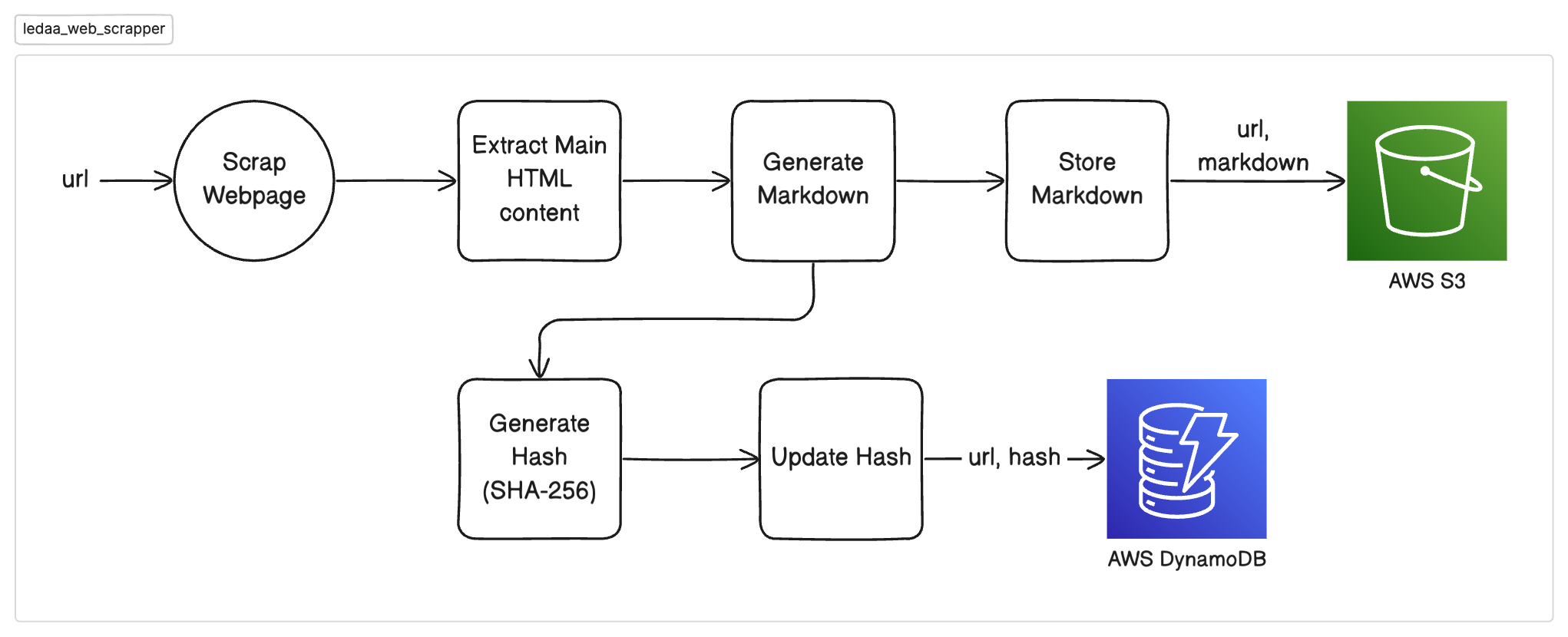
ledaa_load_dataLambda function passing it the URL of webpage. ledaa_load_dataLambda function invokes theledaa_text_splitterLambda function to initiate the process of scraping data from a given URL and to get a list of strings (representing text chunks or documents) which will be used in data ingestion.ledaa_text_splitterLambda function invokes theledaa_web_scrapperLambda function to scrape the URL and store the processed markdown data in S3.ledaa_web_scrapperfunction also stores the hash of the processed data in DynamoDB which will later be compared byledaa_updates_scannerfunction to detect changes.- On receiving processed document chunks back,
ledaa_load_dataLambda function stores the data in the vector store.
Below you can see the process flow of some of the core components:
Process flow for Updates Scanner (ledaa_updates_scanner):
Process flow for Load Data (ledaa_load_data):
Process flow for Web Scrapper (ledaa_web_scrapper):
How to use it?
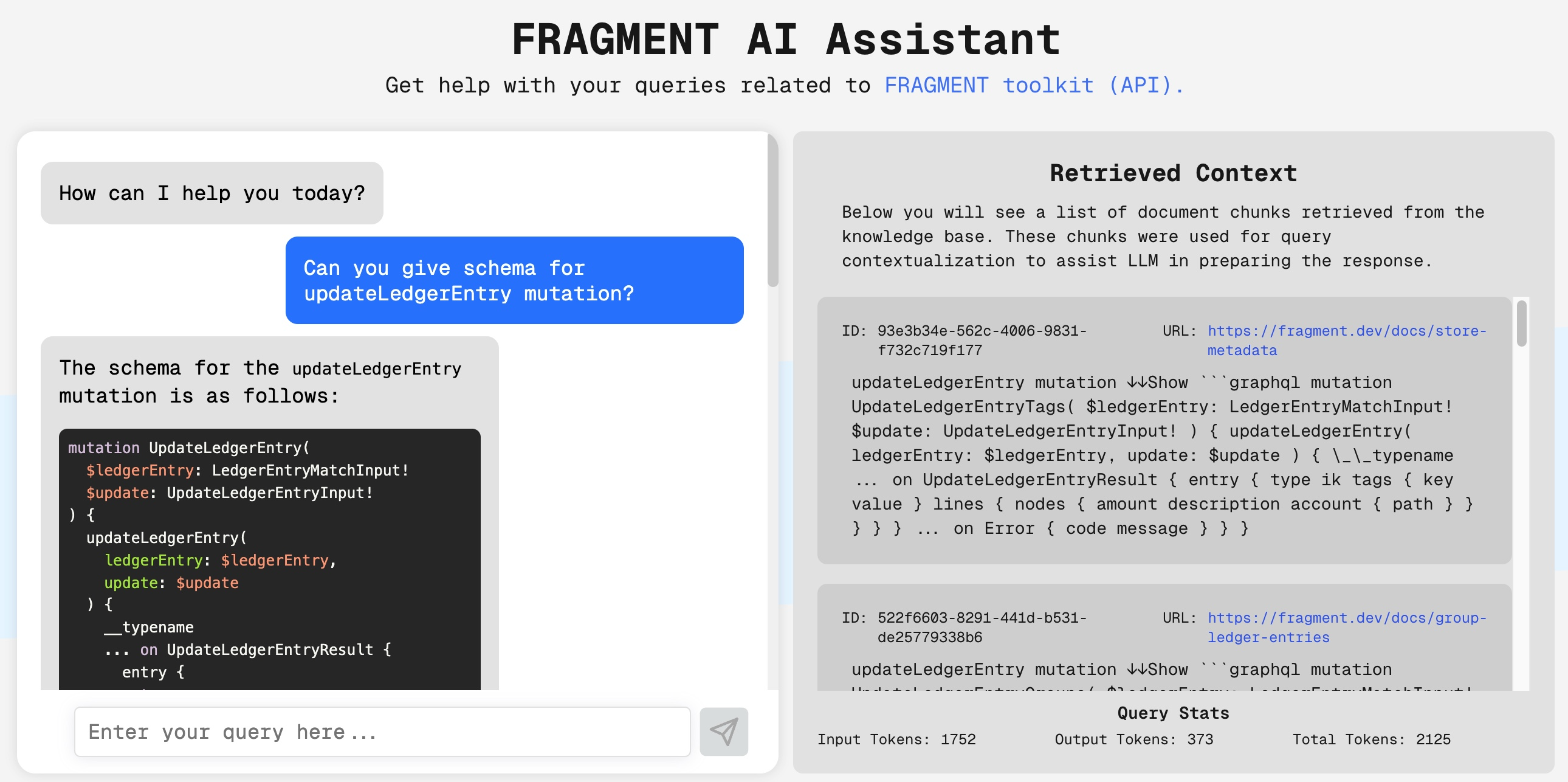
You can interact with the AI Assistant from the FRAGMENT AI Assistant website or using the chat interface below. You can ask questions related to FRAGMENT and the AI Assistant will try to answer them to the best of its abilities. Under the Retrieved Context section, you can also view the document chunks that were retrieved from the knowledge base and used as context by the LLM for generating the answer.
The frontend website was developed using Next.js and designed using Tailwind CSS. Moreover, the chat component was implemented using deep-chat-react package.
To provide a more deeper look into how the answers are being generated, a section called Retrieved Context has been added to displays the document chunks that were retrieved from the knowledge base and used as context by the LLM for generating the answer for a given query. These document chunks are retrieved from the vector store based on the user query and are used to enrich the user query with FRAGMENT specific information.
Technologies Used
AWS + Terraform
More of the projects components are deployed as AWS Lambda functions using Terraform for infrastructure as code (IaC) to manage the deployment and configuration of the AWS resources. The Updates Scanner or ledaa_updates_scanner lambda function is scheduled to run at a specific interval using AWS EventBridge Scheduler.
RAG Model (LangChain, Pinecone, Google Generative AI)
There are two components to RAG:
- Embeddings Generation and Storage: We use Google’s
models/text-embeddings-004embedding model through Google Generative AI to generate embeddings for document chunks. We then store these embeddings in a Pinecone serverless vector store index. - Context Retrieval and Answer Generation: We again use the same Google’s embedding model to embed the query and retrieve the most relevant document chunks from the Pinecone vector store. We then pass on the query + retrieved context documents to Google’s
Gemini 2.0 FlashLLM model to generate the final answer.
We use LangChain to orchestrate the whole embeddings generation + storage and context retrieval + answer generation process.
Pinecone
Pinecone is a managed vector database that provides a serverless vector store index for storing and querying embeddings. We use Pinecone to store the embeddings of the document chunks and to retrieve the most relevant document chunks based on the user query.
Other alternatives to Pinecone, some open source, are Elasitcsearch, Milvus, and AWS OpenSearch Service. For this project I chose Pinecone because it was the easiest to setup and performs exceptionally well. Moreover, it provides a free tier which is great for testing and development purposes. Deploying your own self-hosted vector store is not too complicated but requires some minimum compute resources which are usually beyond cloud free tier limits.
What’s next?
Below are some of the improvements and future enhancements that can be made to the AI Assistant:
Improvements in Data Ingestion & Retrieval Performance
- Semantic Chunking: Use semantic chunking to split the text into more meaningful chunks. For example, semantic splitting of code blocks, lists, tables, etc.
- Hypothetical Questions-Context Embeddings: Generate and add hypothetical questions for each data chunks before embedding them. This will help in better context retrieval, since there will be high chances that the user query will be similar to the hypothetical questions.
- Better Markdown Text Splitting: Improve the markdown text splitting strategy to handle more complex markdown structures.
Beyond Chatbot
- Voice-enabled AI Assistant: Add the ability to interact with the AI Assistant by providing queries through voice.
- Optimized Coding Assistant: Create a specialized AI Assistant that can help developers with FRAGMENT specific coding tasks, for instance, generating code snippets, debugging, etc. in VS Code.
- Agentic AI Assistant with Tools: Integrate tool calling ability into the AI Assistant, for example, to allow automatic deployment of code to AWS or to run tests, or even to generate and send reports to a specific email address.
Conclusion
This project demonstrated the FRAGMENT AI Assistant. This conversational AI assistant can help users answer queries related to FRAGMENT toolkit (API, SDKs, etc.). The AI Assistant is powered by RAG model with the FRAGMENT documentation website serving as source of ground truth and knowledge base. The project also demonstrated handling of source data updates in the knowledge base more efficiently and in real-time.
The projects uses a combination of Google Generative AI, Pinecone, LangChain, and AWS to provide a reliable, accurate, and efficient AI Assistant.
To handle ground truth data updates efficiently, the project implements an efficient document-level (i.e., URL-level) data ingestion pipeline that can be triggered on detecting changes in the content of the FRAGMENT documentation website.
I hope you found value from this brief and that you will enjoy using the FRAGMENT AI Assistant. If you have any questions or feedback, feel free to reach out to me via email at pranavcybsec [at] gmail [dot] com.